主题
黑盒 vs 白盒
一面千识关于生产高质量专家数据的思考:
数据已成为基座模型和Agent公司核心的产品/知识产权。为了提升核心能力和数据安全性,构建一个高效透明的数据收集和标注流程至关重要。
标注团队的素养是影响数据质量的最大杠杆。过去,对于非专业性工作,质检流程和工具是提升质量的关键,但现在,标注员也必须是真正的专家,才能推动模型能力的前沿发展。
迭代速度对于持续改进你的模型和 Agent至关重要。你的实验进度不应该被数据项目合同谈判的进度掣肘。
现状
不幸的是,研究团队目前用于收集专家数据的两种方式都不完美:
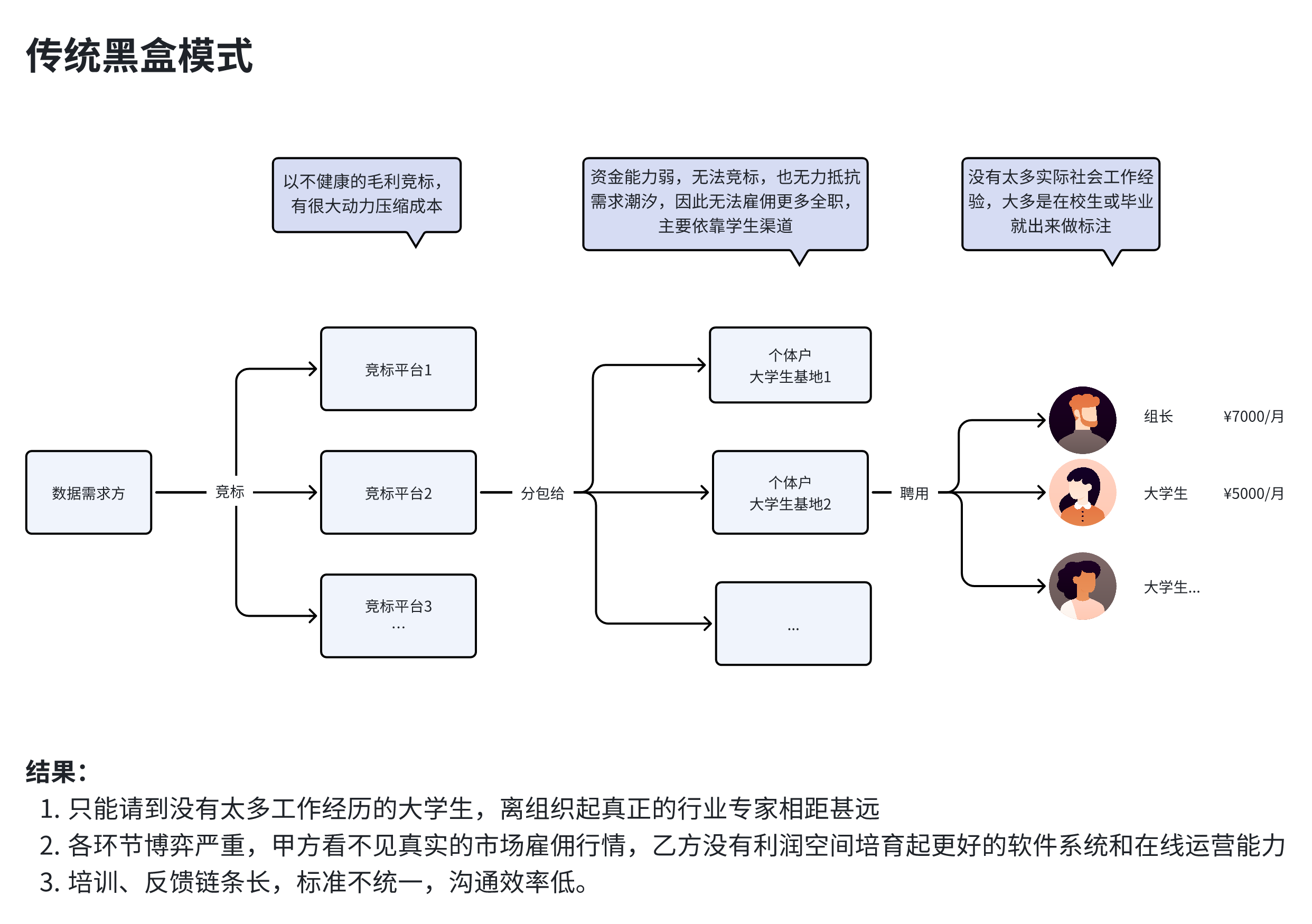
将整个数据收集/标注工作外包给第三方供应商,导致:
实验启动速度较慢,因为需要花时间与供应商协商任务的价格以及沟通反馈。
数据安全隐患,你无法确认数据是否被倒卖,尤其是在供应商层层将任务转包的情况下。
标注员的成本和质量不透明,因为供应商可能会通过掩盖真实工时和标注人员背景来降低成本。
自行组建数据标注团队,这将导致:
更高的固定成本,因为要维护更大的内部数据标注团队。
需要不断为标注团队寻找、筛选、雇用、管理合适的标注员。
在非核心业务的运营上花费大量时间和资源。
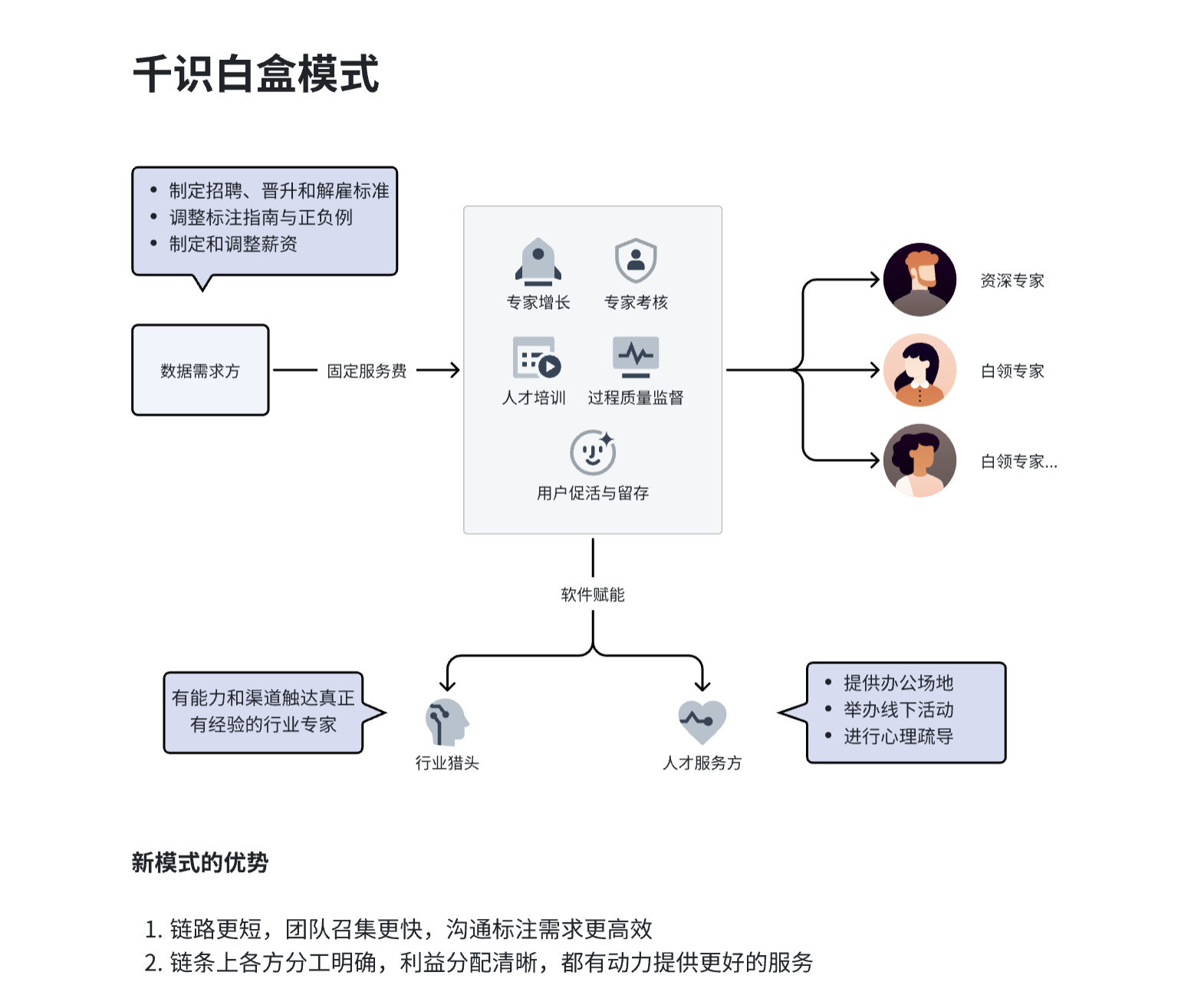
一面千识的目标是通过"白盒"方法,帮助AI 团队实现两全其美,而不是像数据供应商常用的"黑盒"方法。白盒模式的特点是:
简单的按小时计费,支持快速启动和暂停,随时修改团队人才画像。
无需花费时间自行寻找、管理和培训领域专家。
让AI 团队能自主掌控数据,无需担心数据安全问题。
黑盒 vs 白盒
黑盒与白盒两种方式的更详细对比:
| 对比内容 | 传统黑盒模式 | 千识白盒模式 |
|---|---|---|
| 迭代速度 | 每次迭代都要花时间与供应商就每个任务的价格进行协商,算法团队、供应商和标注员之间多层级传话,沟通效率低,信息失真 | 每次启动新项目时无需重新议价,只需支付固定比例的服务费,直接与领域专家合作 |
| 数据安全 | 通过多层供应商层层转包,存在被未知标注员泄露的风险 | 自行决定使用何种标注平台与部署位置,对参与项目的标注员背景有高透明度,对数据和知识产权有控制权 |
| 成本结构 | 不透明的供应商利润率 | 完全透明的领域专家薪酬 |
白盒模式如何运作
明确需求和定价范围
我们会根据对AI 团队需求的初步理解,提供定制化的提案,并就数据分布、数据量以及优化目标等具体问题收集反馈。
每次启动新项目时,不需要冗长的定价讨论,我们只收取领域专家薪酬的固定百分比。
甄选高质量专家
我们会综合考虑面试、工作经验、教育背景、GitHub 资料、论文引用量等多项因素,从人才库中为特定项目寻找最合适的领域专家。
我们会在推进项目之前,完整展示所有被选中的领域专家筛选过程,确保全程透明。
设计并搭建流程
使用我们的平台可以通过我们的工具来快速搭建满足各种训练目标的工作流和数据Pipeline。
我们有一套SOP文档和流程,来帮助用户快速上,包括操作指南、风格指南、评分标准和工作流设计等,也可以根据项目需求定制修改这些内容。
同时我们还会协助建立质量保证体系,从多轮审核工作流到 Majority Vote投票机制,具体方案会根据任务类型和质量要求进行调整。
持续衡量关键指标
我们定义了一套关键指标体系,用于监控数据的质量、产量和成本效率,既包括项目整体情况,也包括每位领域专家的表现。
根据项目的不同,这些指标可能更多或更少。尤其是质量相关指标,通常依赖具体项目的背景,因此我们经常为每个项目制定专门的评分标准,以定义领域专家工作的质量。
根据绩效表现和需求变化调整人员
在领域专家表现不佳或项目不再需要时,我们会通知并将其移除。我们会根据相关指标主动进行此操作。
如果AI 团队有新的需求,我们会在数小时到数天内寻找、筛选并引入新的领域专家。
我们希望通过白盒模式,让AI 团队能够兼得自建数据团队和外包数据供应商的双重优势。