主题
怎么度量与提升Human Data质量
高质量的人类标注数据是现代深度学习模型能否在真实世界中泛化的关键。那么,究竟什么样的数据才能称得上"高质量"?我们应从哪些维度来理解和定义?又有哪些环节决定了人类数据的质量?
什么才算是高质量数据?一个常见但片面的观点是:凡是能让模型在评估集上涨分的数据都是高质量的。但如果训练的目标仅仅是提升某个评估集的分数,那么最直接的方式是合成大量风格类似的训练样本以覆盖评估集的分布,这种做法往往并不需要大量人类专家的参与。这个过程更像是在优化考试技巧,而非提升对人类世界的理解能力。
然而,在现实世界中,用户的需求是丰富、多样、非结构化的,远远超出标准评估集所能覆盖的范围。如果模型仅"偏科式"地学习特定任务或领域,其对真实问题的适应能力往往会大打折扣。因此,若我们的目标是让模型尽可能理解和回应复杂多变的人类问题,我们就必须依赖高质量的人类数据。
那么,高质量的人类数据具备哪些特征?一般认为有以下几个维度:
覆盖面广(Coverage):数据应覆盖足够广的人类问题空间,涵盖不同领域、任务和用户意图。这个维度的构建通常需要深度理解任务目标的专家参与,以设计出具有代表性的问题集。
分布合理(Balance):数据分布应反映真实世界任务的复杂性,而不是过度集中在简单、重复的模式中。在高复杂度或高不确定性的领域应投入更多样本,帮助模型学习处理难题的能力。
多样性(Diversity):特别是在涉及人类价值观、情感、文化表达等方面,数据应能体现出不同观点与微妙差异,提供模型做出更具人性判断的训练素材。
准确性与一致性(Correctness & Consistency):数据标签应准确、清晰、一致,避免由于对相近问题提供不同回答或低质量标注带来的训练误导。
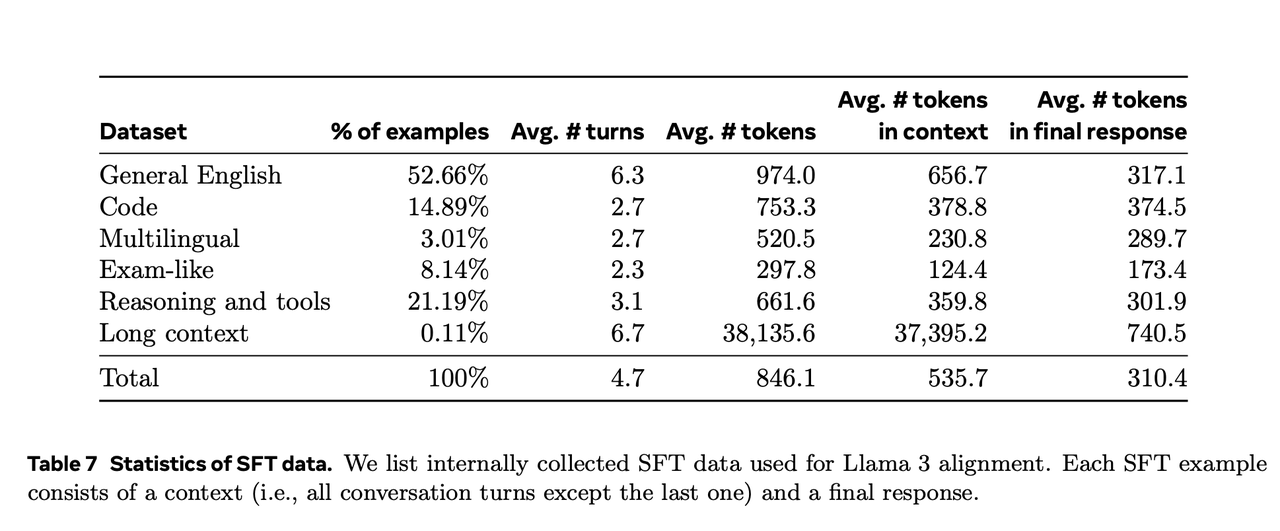
下例:llama3的训练数据分布
过程质量控制
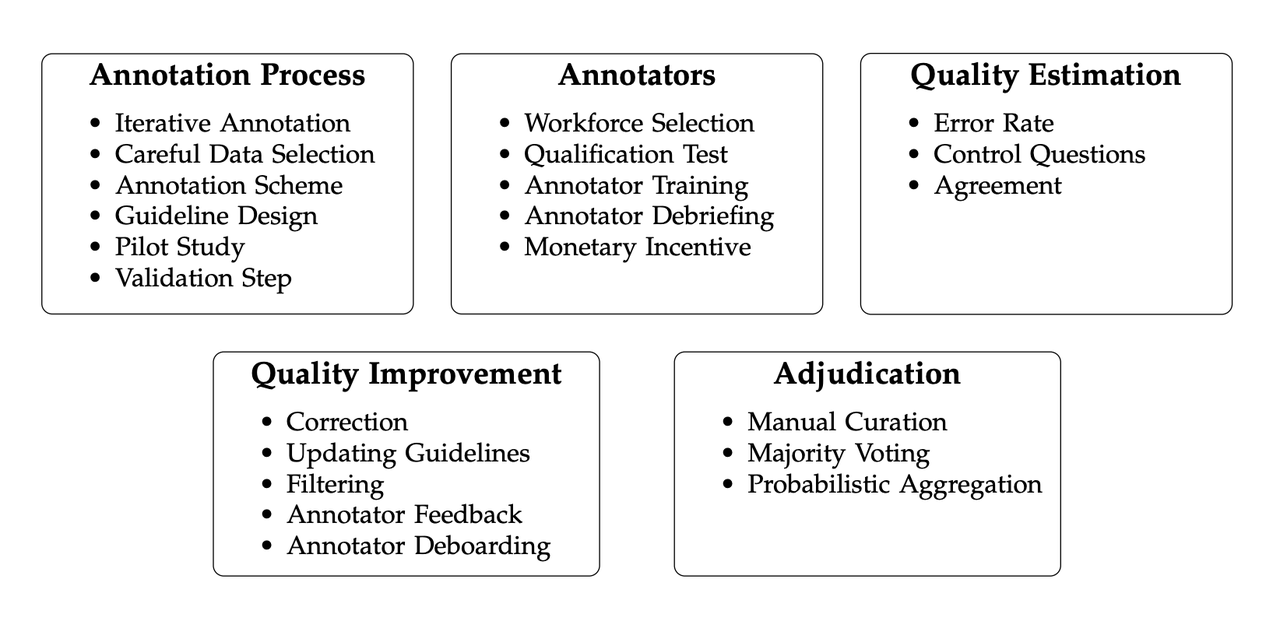
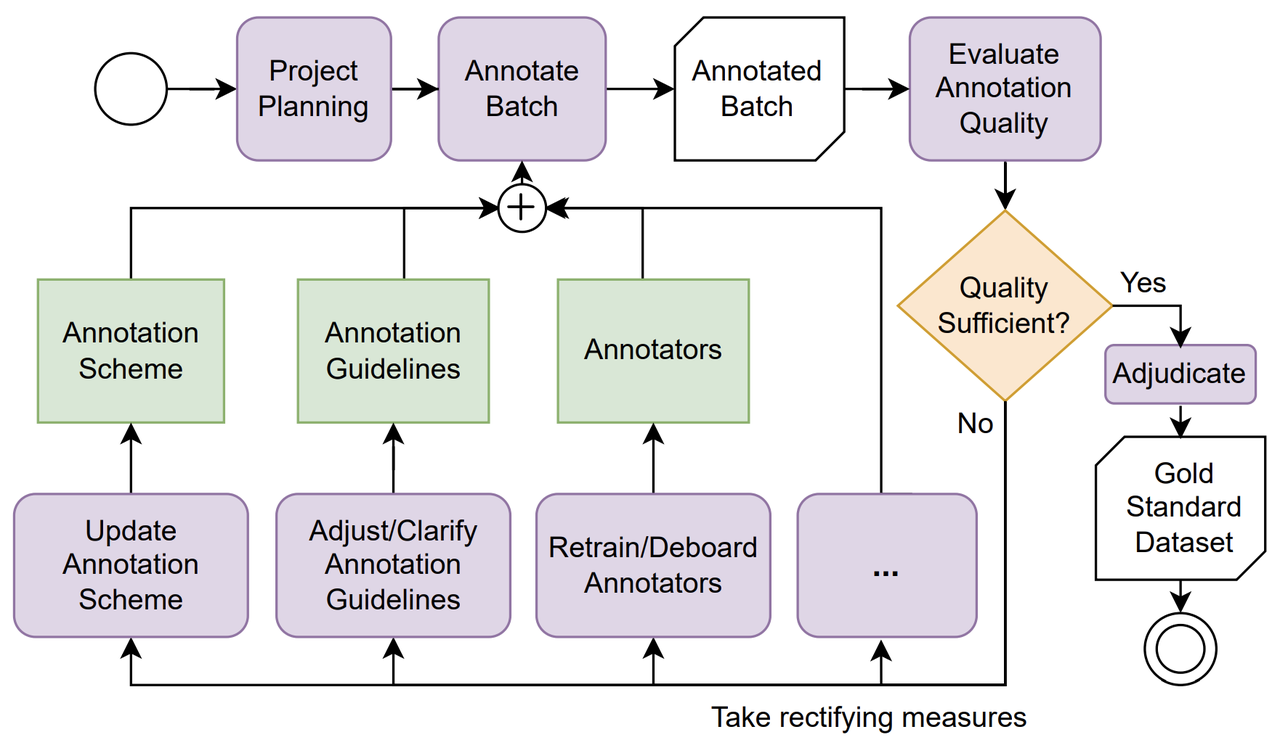
但是,在数据还在产出阶段的时候,很难就上面几个维度来衡量交付的数据质量。这个时候我们就需要先进行标注过程控制。以Thinking Machine联合创始人 翁荔 Lillian Weng 在《Thinking about High-Quality Human Data》中的观点为代表,学术界普遍认为高质量人类数据的产出是一项系统工程,涉及项目管理方法、标注员筛选与激励、任务设计、流程控制等多个环节。管理好整个过程,才有可能产出真正优质的数据。
在《Analyzing Dataset Annotation Quality Management in the Wild》等研究中,更进一步将数据质量分解为五个关键构成:Annotation Process(流程)、Annotators(人员)、Quality Estimation(质量评估)、Quality Improvement(持续改进)与 Adjudication(仲裁机制),充分体现了"过程即质量"的理念。
以下是几个关键实践点:
迭代式标注流程(Iterative Annotation):
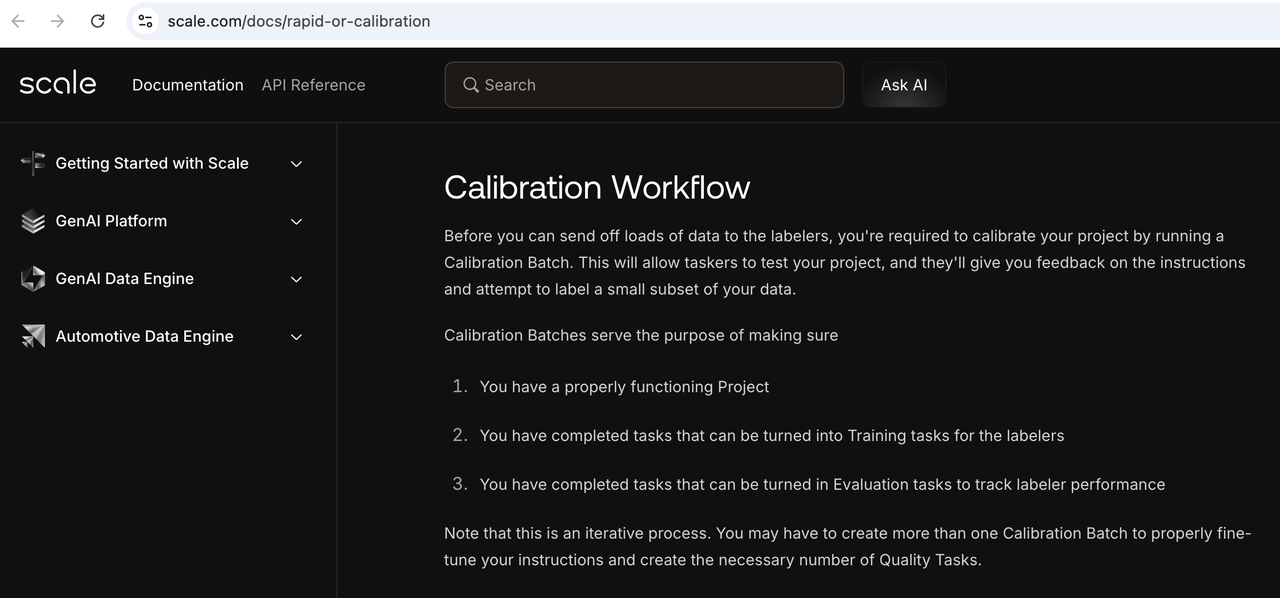
在标注初期,指南模糊、质量标准分歧、标注界面体验欠佳是常态。通过小规模试运行校准流程,反馈修正指引,逐步放量。这与互联网产品中的"小流量A/B实验---优化---规模放量"的思路高度一致。下面以Scale.ai 的 Calibration Workflow为例:
正式数据生产前创建,先由一小批人员进行标注,对于任务是否清晰进行反馈,用于收集边缘案例和优化Instruction,进而提升生产批次(Production Batch)的标注表现。通过标注员的confidence score和审核拒绝率,综合计算一个Calibration Score,针对分数低的部分进行优化或多举例说明,新的标注员上岗即可学习,高质量任务可以转为Quality tasks。
控制任务(Control Tasks):为检测标注员的可靠性和能力水平,系统会随机插入标准答案题目。如果错误率过高,即可暂停该标注员参与。更高级的机制会周期性重复推送相似题目,检测其稳定性和一致性。下例:Labelbox的banchmark label及其插入逻辑

多数投票机制(Majority Vote):对于主观性强的任务,不再盲从"老专家"单一答案,而是引入多位标注员共同投票产生最终答案,避免答案偏向了过时的知识或单点偏见。投票后若标注一致率高,可直接通过;一致率低则进入人工审核。下例中Scale.ai的Consensus Pipeline是majority vote的简单应用
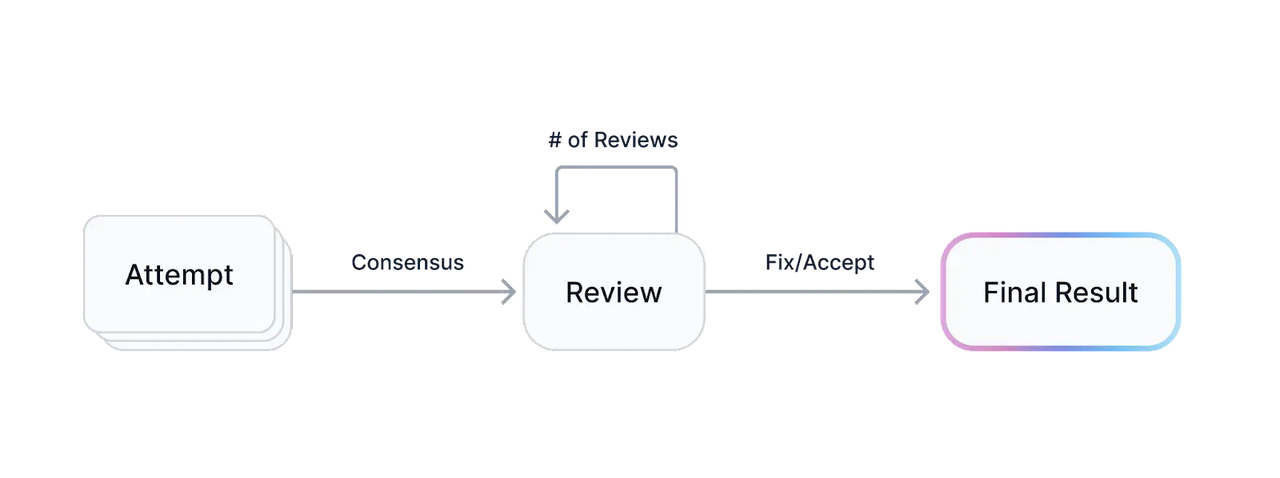
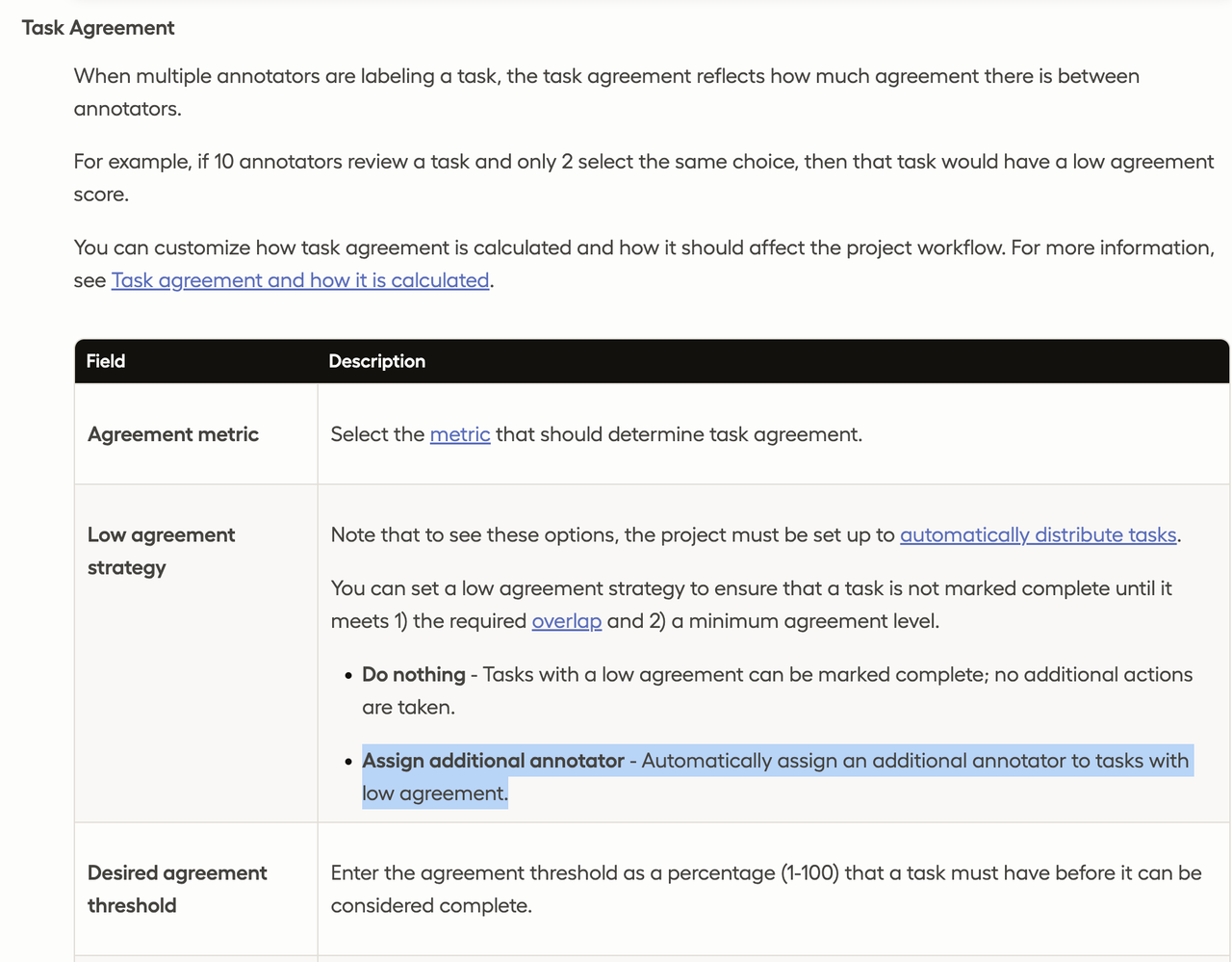
而以label studio为代表实践的则更为复杂,不仅可以拆分人物细节的一致率,还可以将一致率融流程中,为一致率低的任务自动添加更多标注员
向专家级任务过渡:对质量控制的新要求
随着任务从传统图像标注过渡到复杂的语言多轮交互(如 Deep Research、Rubric-based Reward Modeling 等),标注时间从几秒扩展至数小时甚至数天,标注员的角色也从"训练有素的蓝领"转变为"具备背景知识的白领专家"。
这带来了两方面的挑战:
监控方式需升级:传统通过"插题测水平"的方式对标注员进行质量控制,已不足以应对高知识密度任务。更适合的方式是构建"专家文化与工作平台":鼓励沟通、提供反馈空间、建立共识机制,提升标注员的使命感与归属感。用管理白领的方式管理专家型标注员,才能匹配任务本身的复杂度。
激励机制更重要:以 Outlier、Mercor 为例,这些公司采用同行评审+专家抽检制度,并通过严格淘汰机制确保高质量产出。长期表现优秀的标注员会获得更多机会与高额奖励。标注平台正在形成类似"滴滴司机评分系统"的长期信誉体系。
平台的质量控制体系需要在变革中与时俱进,才能在模型不断进化的过程中,持续为实验提供高价值数据。